Codificación de caracteres
Desarrollo de Aplicaciones en Internet
Codificación de caracteres
Desarrollo de Aplicaciones en Internet
Introducción
- Los caracteres tanto en memoria como en otros dispositivos de almacenamiento se representan como secuencias de bits
- Un fichero de texto con una sola letra ‘a’ ocupa 1 byte
- Si el fichero es binario (documento de un procesador de textos, por ejemplo) puede ocupar mucho más
US-ASCII
- El estándar US-ASCII (también conocido como ASCII, American Standard Code for Information Interchange) representa cada carácter con 7 bits
- Su origen se remota a la década de 1960
- Se decidió usar 7 bits porque eran suficientes para representar los 128 caracteres deseados y también para reducir el coste de la transmisión
- En la práctica se usan 8 bits para que coincida con un byte
US-ASCII

ISO/IEC 8859
- Una serie de estándares de codificación de caracteres de 8 bits (256 caracteres diferentes)
- 15 codificaciones de caracteres para diferentes lenguajes
- Los 128 primeros caracteres (0-127) son compatibles con US-ASCII
ISO/IEC 8859
- Si no permitimos el cambio de la codificación de caracteres en mitad de un documento, no es posible mezclar textos en español y ruso, por ejemplo
- En el caso de ficheros de texto, como estos no contienen la codificación que usan, es necesario indicarla explícitamente al programa con el que vayamos a visualizarlos o editarlos
ISO/IEC 8859-1 (Latin 1)
- Inglés, islandés, español, francés, catalán…
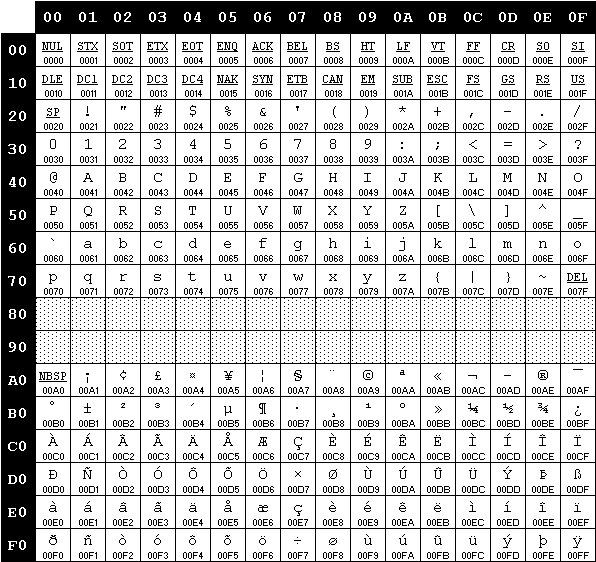
ISO/IEC 8859-15
- Añade a ISO/IEC 8859-1 el símbolo del euro y algún otro como la ligadura ‘œ’ del francés (con ISO/IEC 8859-1 se escriben como ‘oe’)
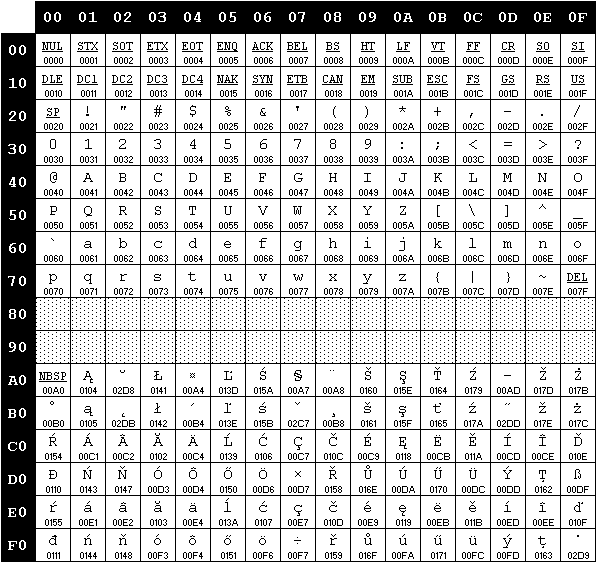
ISO/IEC 8859-2
- Bosnio, croata, checo, eslovaco, húngaro, serbio…
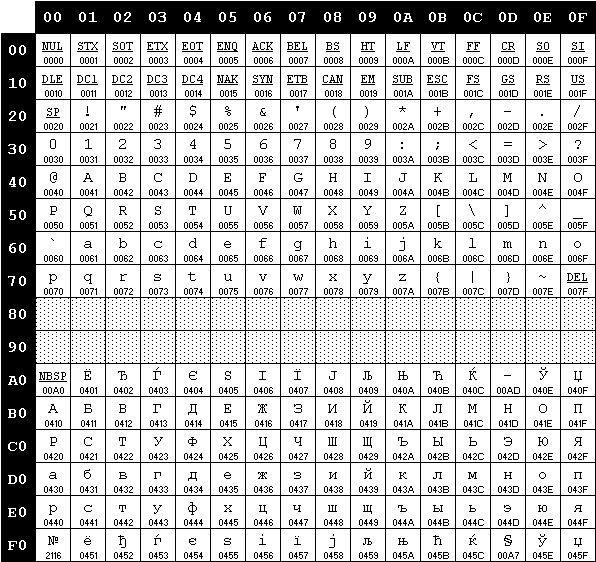
ISO/IEC 8859-5
- Ruso, bielorruso, macedonio, serbio, búlgaro…
Otras codificaciones
- Algunos sistemas operativos incluían codificaciones alternativas (Windows-1252, por ejemplo)
Unicode
- Estándar del Unicode Consortium que intenta reemplazar a todos los anteriores y permite entornos plurilingües
- Cada carácter se identifica mediante un número o punto de código
- Los puntos de código no cambian, pero hay diferentes codificaciones: UTF-8, UTF-16, UTF-32, etc.
Unicode
- El estándar Unicode permite 1.114.112 puntos de código
- Actualmente están asignados unos 140.000, incluyendo emojis (‘🥘’, U+1F958), caracteres de alfabetos antiguos, etc.
Codificaciones de caracteres de Unicode
- UTF-8 es la más usada en la web: 1 byte para los primeros 128 puntos de código (iguales a los de US-ASCII) y hasta 4 para los restantes
- UTF-16: 2 o 4 bytes por carácter
- UTF-32: 4 bytes por carácter
Cómo usar Unicode
- Usar un editor de texto que lo soporte (Unicode suele ser la codificación por defecto hoy en día)
- Usar un lenguaje de programación que lo soporte (muchos lo hacen de forma nativa)
- Usar un tipo de letra adecuado (ningún tipo de letra soporta todos los caracteres de Unicode)
Programar con caracteres de Unicode
- Ejemplos en Java:
var Omega = 'Ω';
var Omega = '\u03A9'; // compatible con cualquier entorno
public static void m (void) {
int ဆဆဆ = 100; // caracteres en birmano
System.out.println("ကောင်းသောနေ.ပါ " + ဆဆဆ);
}Entidades de HTML
- En desuso
- Permiten representar algunos caracteres que no son US-ASCII dentro de un documento HTML
- El carácter ‘Ã’ se puede representar como uno de los siguientes:
Ã
Ã
ÃEjemplos
- El carácter ‘a’ (LATIN SMALL LETTER A, U+0061) en US-ASCII es 01100001 (61 en hexadecimal, x61), igual que en ISO/IEC 8859 y que en UTF-8; en UTF-16 es 11111110 11111111 00000000 01100001 (xFEFF0061)
- El carácter ‘á’ (LATIN SMALL LETTER A WITH ACUTE, U+00E1) se representa en ISO/IEC 8859-15 como xE1 y en UTF-8 como xC3A1
Ejemplos
- El carácter ‘Ã’ se representa en ISO/IEC 8859-15 como xC3
- El carácter ‘¡’ se representa en ISO/IEC 8859-15 como xA1
Problema
- Teniendo en cuenta los datos de las diapositivas anteriores, ¿cómo se ve un fichero de texto escrito en UTF-8 que contiene guaraná en un editor de texto configurado para ISO/IEC 8859-15?
- ¿Cómo se ve un fichero de texto escrito en ISO/IEC 8859-1 que contiene guaraná en un editor de texto configurado para UTF-8?
UTF-8 en páginas web
- Configurar el servidor para que informe al cliente de que la codificación es UTF-8: añadir a la petición y a la respuesta la cabecera HTTP:
Content-Type: text/html; charset=utf-8- Indicar la codificación en el head de HTML:
<meta charset="utf-8">o antiguamente:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />Precacuciones
- En JavaScript, que usa UTF-16, “🤦🏻♂️”.length == 7 (man facepalming: light skin tone); el número de bytes en memoria es 14
- La cadena contiene 5 valores de Unicode (explicación): persona palmeándose la cara, color de piel, ligadura de códigos, hombre, no monocromo
- En otros lenguajes la longitud puede ser diferente, pero pocos lenguajes dan 1 como longitud